Aufbau von DataBaskets
DataBaskets sind Container für Informationen, welche Transaktionen beschreiben. Dazu gehören Entfernen, Hinzufügen oder Editieren von CatalogItems oder StockItems. Die Informationen selbst werden durch Objekte vom Typ DataBasketEntry repräsentiert. DataBasketEntries werden allerdings nicht direkt im DataBasket gespeichert. Stattdessen enthält der DataBasket einen oder mehrere SubDataBaskets, welche ihrerseits die DataBasketEntries beherbergen.
Dadurch, dass mehrere SubDataBaskets gespeichert werden können, erhält man die Möglichkeit, mit einem DataBasket mehrere "Speicherpunkte" zu unterhalten. Um das dadurch eingeführte Problem der möglichen Datenkorruption durch Inkonsistenzen muss sich der Programmierer kümmern, das Framework führt keine Konsistenzprüfungen durch.
In der Praxis wird meist ein DataBasket mit genau einem SubDataBasket verwendet. Das ist auch die Standardkonfiguration beim Erzeugen eines neuen DataBaskets.
Aufbau von DataBasketEntries
DataBasketEntries beschreiben Transaktionen von Stock- oder CatalogItems und besitzen dafür die folgenden Attribute:
mainKey | Unterscheidung des Typs von DataBasketEntry: für StockItems oder für CatalogItems. |
secondaryKey | Der Key des Catalog- oder StockItems, für welches der DataBasketEntry eine Transaktion beschreibt. |
value | Das Catalog- oder StockItem, für welches der DataBasketEntry eine Transaktion beschreibt. Der Key dieses Items entspricht genau dem secondaryKey des DataBasketEntrys. |
source | Der Container (Catalog oder Stock), aus dem das Item entfernt wurde. |
destination | Der Container (Catalog oder Stock), zu dem das Item hinzugefügt wurde. |
owner | Der DataBasket, zu dem dieser DataBasketEntry gehört. |
handled | Beschreibt, ob schon ein commit oder rollback auf diesem DataBasketEntry durchgeführt wurde. |
DataBasketConditions
DataBasketConditions sind Filter für DataBasketEntries. Deshalb besitzen sie auch die meisten der Attribute von DataBasketEntries:
mainKey | Unterscheidung des Typs von DataBasketEntry: für StockItems oder für CatalogItems. |
secondaryKey | Der Key des Catalog- oder StockItems, für welches der DataBasketEntry eine Transaktion beschreibt. |
value | Das Catalog- oder StockItem, für welches der DataBasketEntry eine Transaktion beschreibt. |
source | Der Container, aus dem das Item entfernt wurde. |
destination | Der Container, zu dem das Item hinzugefügt wurde. |
Außerdem gibt es eine match() Methode, die standardmäßig true zurückliefert, in speziellen Fällen aber überschrieben werden muss (siehe checkItems(boolean fGet)).
Falls ein Attribut den Wert null besitzt, so wird dies vom Framework dahingehend interpretiert, dass der Filter bei diesem Attribut immer passt. Es gibt sozusagen kein Filterkriterium, welches angewandt werden müsste.
DataBasketConditions kommen unter Anderem beim Iterieren über SubDataBaskets zur Anwendung (siehe Iterieren über SubDataBaskets).
SubDataBaskets
Aufbau von SubDataBaskets
Das Herzstück eines SubDataBaskets ist eine HashMap dbeCatagories. In ihr befinden sich wiederum zwei HashMaps, eine für StockItemDBEntries und eine für CatalogItemDataBasketEntries. Jede dieser zwei Maps enthält Listen. In diesen Listen stehen die eigentlichen DataBasketEntry-Objekte. Der Key, unter dem die Listen in ihrer Map gespeichert sind, ist gleich dem Key des Items, welches in Form eines DataBasketEntrys gespeichert werden soll (also dem secondaryKey des DataBasketEntrys). Damit ist es möglich, Items gleichen Typs und Namens, z.B. zwei CatalogItems, die beide den Namen "item1" haben, im selben SubDataBasket zu speichern, sprich, Kollisionen zu erlauben.
Abbildung
2.1 verdeutlicht den Aufbau noch einmal grafisch.
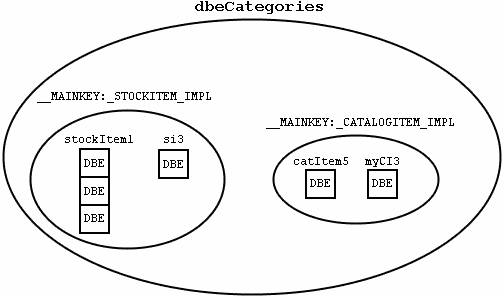
Abbildung 2.1: Aufbau eines SubDataBaskets
An dieser Stelle bietet sich ein Beispiel an: Wenn drei mal je fünf StockItems "item1" aus einem CountingStock entfernt werden, gibt es drei DataBasketEntries, die in einer gemeinsamen Liste in der Map für die StockItemDBEntries stehen. Auf diese Liste kann vom Framework über den Key "item1" zugegriffen werden. Die drei DataBasketEntries sehen hier identisch aus, und zwar folgendermaßen:
mainKey | __MAINKEY:_STOCKITEM_IMPL |
secondaryKey | item1 |
value | 5 (bei Items für StoringStocks stände hier das tatsächliche StockItem Objekt) |
source | das Stock Objekt, aus dem die Items entfernt wurden |
destination | null |
Iterieren über SubDataBaskets
SubDataBaskets haben ihren eigenen Iterator, auf den mit der Methode iterator(DataBasketCondition dbc, boolean fAllowRemove, boolean fShowHandled) zugegriffen werden kann.
Der verschachtelte Aufbau von SubDataBaskets macht es nötig, in mehreren Stufen zu iterieren:
- über die HashMap
dbeCategories. Der verwendete Iterator heißtiCategories. - über die HashMaps, welche die Listen mit StockItemDBEntries und CatalogItemDataBasketEntries enthalten. Der verwendete Iterator heißt
iSubCategories. - über die Listen in den SubCategories, welche ihrerseits die eigentlichen DataBasketEntries enthalten. Der verwendete Iterator heißt
iItems.
Alle drei Iteratoren sind global in der Klasse SubDataBasket definiert.
hasNext() und next()
Die Methoden hasNext() und next() machen beide Gebrauch von findNext(). Während hasNext() findNext() mit dem Parameter fGet = false aufruft und den erhaltenen booleschen Rückgabewert selbst zurückliefert, ist fGet für next() true. Der Rückgabewert ist die globale Variable dbeCurrent, in welcher der nächste zurückzuliefernde DataBasketEntry abgelegt wurde. Das Speichern des Entrys in dbeCurrent geschieht in der Methode checkItems(boolean fGet).
findNext(boolean fGet)
Die Methode besteht aus einer do-while-Schleife. Zu Beginn wird checkSubCategories(boolean fGet) aufgerufen. Wird dabei true zurückgeliefert, so wurde in der aktuellen Category (entweder die Map für StockItems oder die für CatalogItems) eine SubCategory mit passendem DataBasketEntry gefunden und, falls fGet true ist, wurde dieser Entry in dbeCurrent gespeichert. Es wird true zurückgeliefert und die Methode ist beendet.
Konnte kein DataBasketEntry gefunden werden, muss die nächste Category, falls es noch eine gibt, durchsucht werden. Diese erhält man, indem man den Iterator iCategories weiterlaufen lässt. Auf der neuen Category wird ein Iterator erzeugt und als iSubCategories gespeichert, er wird dann beim nächsten Durchlauf der do-while-Schleife von checkSubCategories() verwendet, um über die SubCategories dieser Category zu iterieren. Falls dem Iterator des DataBaskets im Konstruktor eine DataBasketCondition übergeben wurde, wird vor dem Weiterspringen zur nächsten Category überprüft, ob der mainKey der Condition null ist, bzw. ob die mainKeys von DataBasketEntry und DataBasketCondition identisch sind. Falls nicht, würde diese Category ausgelassen und im folgenden Durchlauf der do-while-Schleife die nächste untersucht. Gibt es keine Category mehr, wird findNext() mit return false verlassen.
checkSubCategories(boolean fGet)
Die Methode arbeitet absolut analog zu findNext(), nur eine Hierarchieebene tiefer. So wird zu Beginn der do-while-Schleife mit checkItems(boolean fGet) überprüft, ob passende DataBasketEntries in den Items der SubCategory zu finden sind. Falls ja, wird die Methode mit return true beendet, andernfalls wird zur nächsten SubCategory gegangen, auf der der Iterator mItems definiert wird, um über die Items der SubCategory zu laufen. Auch hier muss wieder die DataBasketCondition beachtet werden. Eine SubCategory kommt in Frage, wenn der secondaryKey der Condition mit dem Key der SubCategory übereinstimmt oder null ist.
checkItems(boolean fGet)
Die Methode überprüft zuerst dbeNext. Wenn es nicht null ist, wurde in einem früheren Iterationsschritt (ausgelöst von hasNext()) schon das Vorhandensein eines passenden DataBasketEntrys festgestellt und es wird true zurückgeliefert. Wenn zusätzlich fGet true ist, also checkItems() von der next() Methode aufgerufen wurde, wird vorher dbeNext in dbeCurrent gespeichert. Wenn dbeNext aber null ist, ist nicht bekannt, ob es einen weiteren DataBasketEntry gibt. Deshalb wird unter Benutzung von iItems über die aktuelle Liste von Items iteriert. Für jeden DataBasketEntry wird überprüft, ob er den Suchkritieren entspricht. Das ist der Fall wenn:
- er "unbearbeitet" ist (siehe Commit von DataBasketEntries) oder er "bearbeitet" ist und zugleich
fShowHandled(Parameter deriterator()Methode)trueist - die DataBasketCondition
nullist oder auf den DataBasketEntry passt, also insource,destinationundvaluemit ihm übereinstimmt.
Wennvalueder DataBasketConditionnullist, entscheidet stattdessen diematch()Methode der DataBasketCondition, ob die Suchkriterien erfüllt sind. Damit lassen sich komplexere Filterungen durchführen, als es ein bloßes Setzen der Filterattribute ermöglicht. Beispielsweise kann überprüft werden, ob ein Attribut des DataBasketEntrysnullist (zur Erinnerung:nullin einem Attribut der DataBasketCondition bedeutet, alles kann im zugehörigen Attribut des DataBasketEntrys stehen, eine explizite Abfrage nachnullist damit nicht möglich). Anwendung findet diematch()Methode beispielsweise beim Hinzufügen von CatalogItems zu einem Catalog (siehe Hinzufügen eines CatalogItems). Dort wird eine DataBasketCondition erzeugt, die unter Anderem überprüft, ob für einen DataBasketEntry das Attributdestinationgleichnullist und das Attributsourceungleichnull.
Wird ein passender DataBasketEntry gefunden, so wird er in dbeNext gespeichert, oder, wenn fGet true ist, gleich in dbeCurrent. Anschließend wird die Methode mit return true beendet. Wurde in der Liste kein passender Eintrag gefunden, wird false zurückgeliefert.
Commit von DataBasketEntries
Ein commit() wird vom DataBasket an all seine SubDataBaskets weitergeleitet. Es kann eine DataBasketCondition übergeben werden. Das commit() wird dann nur für DataBasketEntries, die auf die DataBasketCondition passen, ausgeführt.
Alternativ kann man mit commitSubBasket() auch einen bestimmten SubDataBasket angeben, für den ein commit durchgeführt werden soll. Es ist allerdings nicht möglich, einzelne SubDataBaskets für ein commit auszuwählen und ihnen gleichzeitig eine DataBasketCondition als Filter mitzugeben. Diese Funktionalität kann aber bei Bedarf leicht in einer Unterklasse von DataBasketImpl realisiert werden.
SubDataBaskets leiten das commit zu ihren Entries. Es wird mit der übergebenen DataBasketCondition über den SubDataBasket iteriert (siehe Iterieren über SubDataBaskets). Auf jeden DataBasketEntry, der vom Iterator geliefert wird, wird ein commit() ausgeführt, sofern der DataBasketEntry noch nicht als handled (bearbeitet) markiert ist. Anschließend wird er mit der remove() Methode des Iterators aus dem SubDataBasket entfernt.
Beim commit eines DataBasketEntries wird handled auf true gesetzt, um anzuzeigen, dass dieser Entry bearbeitet wurde und keine aktuelle Transaktion mehr beschreibt. Danach wird für die Quelle des DataBasketEntries, die im Feld source steht, ein commitRemove() ausgeführt, für das Ziel des Entrys, welches vom Attribut destination beschrieben wird, ein commitAdd(). Damit werden temporär hinzugefügte oder entfernte Items in ihren Quellen fest hinzugefügt bzw. komplett entfernt. Für Details zu diesen Methoden sei auf die Dokumentation von Katalogen und Stocks verwiesen.
Rollback von DataBasketEntries
Ein rollback() funktioniert analog zum commit().
Beim rollback() auf dem DataBasketEntry wird ein rollbackAdd() bzw. ein rollbackRemove() ausgeführt, was zur Folge hat, dass temporär zu einer Quelle hinzugefügte Items wieder entfernt werden und temporär entfernte Items wieder hinzugefügt.
Auch zu diesen Methoden stehen Details in der Dokumentation von Catalogs und Stocks.
Die Bedeutung des Flags "handled"
Das Flag handled scheint auf den ersten Blick überflüssig zu sein, schließlich wird der abgearbeitete DataBasketEntry sofort aus dem SubDataBasket entfernt, wenn auf diesem ein commit() oder rollback() ausgeführt wird. Allerdings ist es möglich, für einen einzelnen DataBasketEntry "von Hand" ein commit() oder rollback() auszuführen und ihn einfach nicht aus dem SubDataBasket zu löschen. Um in solchen Fällen Datenintegrität zu sichern, werden bearbeitete DataBasketEntries immer mit handled entwertet.
 Einleitung Einleitung | Catalogs  |